Skal vi nu skifte AI model igen?
Evaluering af sprogmodeller - hvordan?

En ny model stort set hver uge
Hver familie udgiver nye versioner flere gange om året. Hvordan følger man med?
Alle siger de er bedst
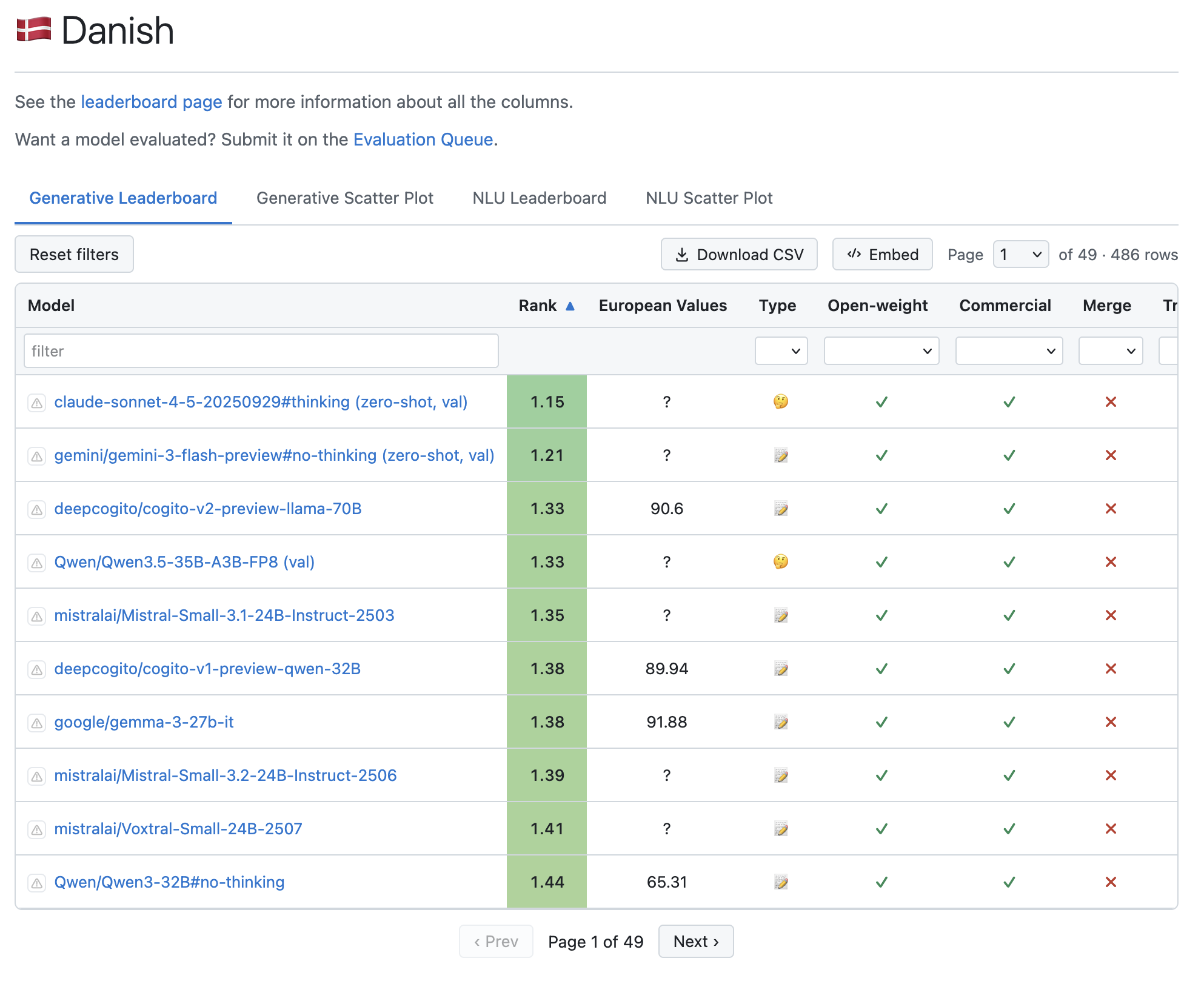
Hvem skal man tro? Og passer det også på dansk?
Vi har brug for uvildig evaluering
Producenten skal ikke selv afgøre, om deres model er god nok.
Fra model til sammenlignelige tal
Alle slags sprogmodeller
Encodere
BERT, RoBERTa, ModernBERT m.fl. Fintunes på hver opgave før evaluering.
Base decodere
Forhåndstrænede sprogmodeller uden instruction tuning. Evalueres via few-shot prompting.
Instruction-tuned decodere
GPT, Claude, Gemini, Llama-Instruct m.fl. Zero-shot eller few-shot via chat-format.
Reasoning-modeller
o1, DeepSeek-R1, Claude Thinking. Eksplicit tænkeproces før svar.
Fra model til sammenlignelige tal
Ti opgaver, samme protokol
Fra model til sammenlignelige tal
Et enkelt tal er aldrig nok.
Hver model køres 10 gange på bootstrappede testsæt, så scoren kommer med et 95 %-konfidensinterval i stedet for et enkelt tal. Det øger troværdigheden.
Ingen signifikant forskel på B og C. A er målbart bedst. D ligger klart bagest.
Sådan kombineres scoren på tværs af opgaver
Rangér
For hver opgave rangerer vi modellerne. Hvis to modeller ikke er statistisk forskellige, deler de samme rang.
Indkorporér standardafvigelser
I stedet for at bruge rangene direkte, udregner vi rank score, som også tager højde for hvis modellerne er tæt på eller langt fra hinanden.
En mode har rank score 1 + σ hvis den er σ standardafvigelser dårligere end den bedste model.
Hvorfor ikke bare gennemsnit?
Opgaverne måler forskellige ting i forskellige skalaer, så et gennemsnit vil give et bias imod metrikker, der varierer mere
Fra model til sammenlignelige tal
Sådan ser det ud i praksis
Alle Europas nationalsprog og flere på vej
Et højt tal er ikke det samme som tillid
En model kan løse opgaven og samtidig være forudindtaget, finde på fakta, eller misforstå europæisk kontekst.
Vi har brug for evalueringer, der måler andet end rå performance.
Tre dimensioner ud over præstation
Europæiske værdier
Forstår modellen den kulturelle og politiske kontekst, vi lever i?
Hallucination
Hvor ofte finder modellen på fakta, der lyder rigtige?
Bias
Behandler modellen forskellige grupper ens?
Stemmer modellens svar overens med EU-borgerens?
European Values Study + World Values Survey
156.658 respondenter på tværs af Europa. Vi udvælger 53 spørgsmål, hvor der er bred EU-konsensus.
13 værdidimensioner
Demokrati, lighed, tillid, civilt engagement m.fl.
34 europæiske sprog
Samme spørgsmål, lokaliseret.
Alignment-score
Hvor tæt ligger modellens svarfordeling på EU-borgerens?
Hallucinations-raten stiger med sværere sprog
Sådan måles det
Modellen får et Wikipedia-uddrag og et spørgsmål. Hver token i svaret klassificeres som hallucineret eller ej, målt mod kilden.
30 europæiske sprog · 5.000 eksempler pr. sprog.
Skadelig bias varierer voldsomt mellem modeller
Omfang
7 dimensioner: køn, alder, etnicitet, religion, seksualitet, handicap, socioøkonomi.
Dansk: 5.404 eksempler, 30 grupper.
Byg dit eget benchmark
from euroeval import Benchmarker, DatasetConfig, TEXT_CLASSIFICATION from euroeval.languages import DANISH MY_CONFIG = DatasetConfig( name="min-eval", pretty_name="Min evaluering", source=dict(train="train.csv", val="val.csv", test="test.csv"), task=TEXT_CLASSIFICATION, languages=[DANISH], labels=["positive", "negative"], ) Benchmarker().benchmark( model="din-model", dataset=MY_CONFIG, )
| text | label |
|---|---|
| Fantastisk service, kommer helt sikkert igen. | positive |
| Maden var kold og personalet uvenligt. | negative |
| text | label |
|---|---|
| Helt okay, ikke det bedste. | positive |
| Skuffende kvalitet til prisen. | negative |
| text | label |
|---|---|
| Bedste oplevelse i lang tid. | positive |
| Aldrig mere, det var skuffende. | negative |
Understøtter alle indbyggede opgaver, inklusiv LLM-as-a-judge. Du kan også let lave din egen opgave.
Egne evalueringer slår generelle leaderboards
Realistisk
Test på data, der ligner det, modellen faktisk skal se i produktion.
Privat
Dine prompts og data ender ikke i et offentligt benchmark. Sværere at "game".
Sammenlignelig
Samme protokol som det offentlige leaderboard. Tal kan direkte sammenlignes.
Benchmarks lyver på interessante måder
Kontaminering
Test-data lækker ind i træningsdata. Et godt benchmark-tal kan betyde, at modellen har set svaret før. Af samme grund udskifter vi ofte evalueringsdatasæt på leaderboards.
Vores anbefaling
Brug leaderboards til at lave en shortlist af kandidatmodeller. Test så disse modeller på din egen private data, før du vælger.
Skift model? Måske, men basér din beslutning på det, der betyder noget for dig
Det er ikke nok at være den bedste til benchmark X. Vælg på baggrund af din egen konkrete use-case.
Tak
Spørgsmål?