Is GPT-4 Performance Getting Worse?
Posted on June 13, 2024
Whenever OpenAI (or any other AI company to be fair) releases a new GPT model, we all tend to assume that the new model is always better than the predecessor - even if that model is also cheaper than the previous models. Even if we assume that this is the case for English, where does this leave the rest of our languages?
In this blog post, I’ll be digging into this question, using the multilingual ScandEval benchmarking framework.
Using the ScandEval benchmarking framework, we benchmarked the three types of GPT-4 architectures that we have seen so far:
- The original GPT-4 architecture, released March 2023 and represented here by the model
gpt-4-0613. This is the one that was rumoured to be a large 8x220B mixture-of-experts model. - The GPT-4-turbo architecture, released November 2023 and represented here by the model
gpt-4-1106-preview. This model is 3x cheaper than the GPT-4 architecture. - The newest GPT-4o architecture (“o” for “omni”), which is a multimodal architecture that can handle both text and images. It was released May 2024, and here represented by the only available iteration
gpt-4o-2024-05-13. The omni model is 2x cheaper than GPT-4-turbo.
The benchmarking framework consists of 7 tasks, and supports evaluating generative models on these tasks in the Germanic languages English, German, Dutch, Danish, Swedish and Norwegian. There is support for Icelandic and Faroese as well, but as these don’t cover all 7 tasks we can’t compare these directly with the other languages and leave them out for this analysis. The tasks are the following:
- Sentiment classification, where the models have to classify texts as having a positive, negative or neutral sentiment.
- Linguistic acceptability, where a text is given and the model has to determine whether the text is grammatically correct or not.
- Named entity recognition, where the model has to locate all the names, locations and organisations in a given text. We do this by having the models output a JSON dictionary with the three types of entities as keys and lists with the entities as values. The new JSON mode is used here with the OpenAI API.
- Extractive question answering, where the model is given a text and a question whose answer exists in the text, and it has to answer the question from the text.
- Summarisation, where a text is given and the model has to summarise it.
- World knowledge, in which a multiple-choice factual question is asked and the model has to select the answer among the answer choices.
- Common-sense reasoning, also a multiple-choice task, where the questions are related to common sense rather than factual knowledge.
A more in-depth description of the first four tasks, including the datasets used, can be found in this paper. The evaluation procedure for generative models can be found an upcoming preprint (should be on ArXiv in a week or so).
The following plot shows how the performance of the GPT-4 architectures have developed for English and the rest of the languages. We normalise GPT-4 performance per language, and observe how the subsequent GPT-4-turbo and GPT-4o models perform on that given language. Increasing values on this plot means that the model is getting worse:
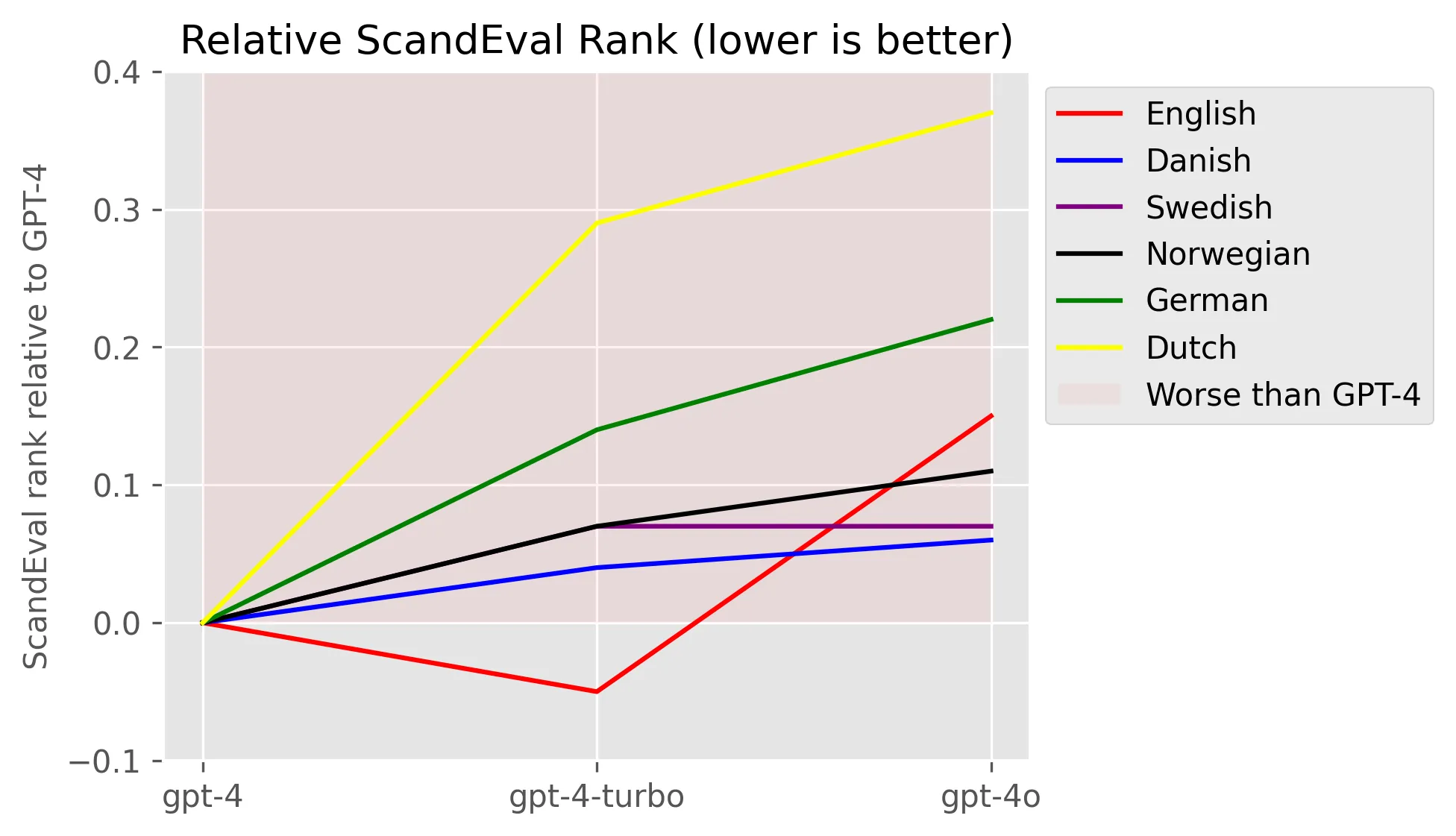
We firstly note that the shift from GPT-4 to GPT-4-turbo improved the English performance while getting worse at all the other languages, which seems to indicate that the model is an “English distilled” version of GPT-4, also explaining how the GPT-4-turbo model is substantially cheaper.
Second, we note that the GPT-4o model continues getting worse at all the languages, where it is interesting that even the English performance got significantly worse. This has been noted anecdotally by several people (see [1], [2], [3], [4], [5], [6], [7]). This is in stark contrast to the LMSYS Arena leaderboard where the GPT-4o model has a solid first place. However, OpenAI had several (anonymised) models on the Arena prior to the GPT-4o release, one of which ended up being GPT-4o in disguise, so one could speculate that there might be some Arena overfitting going on here.
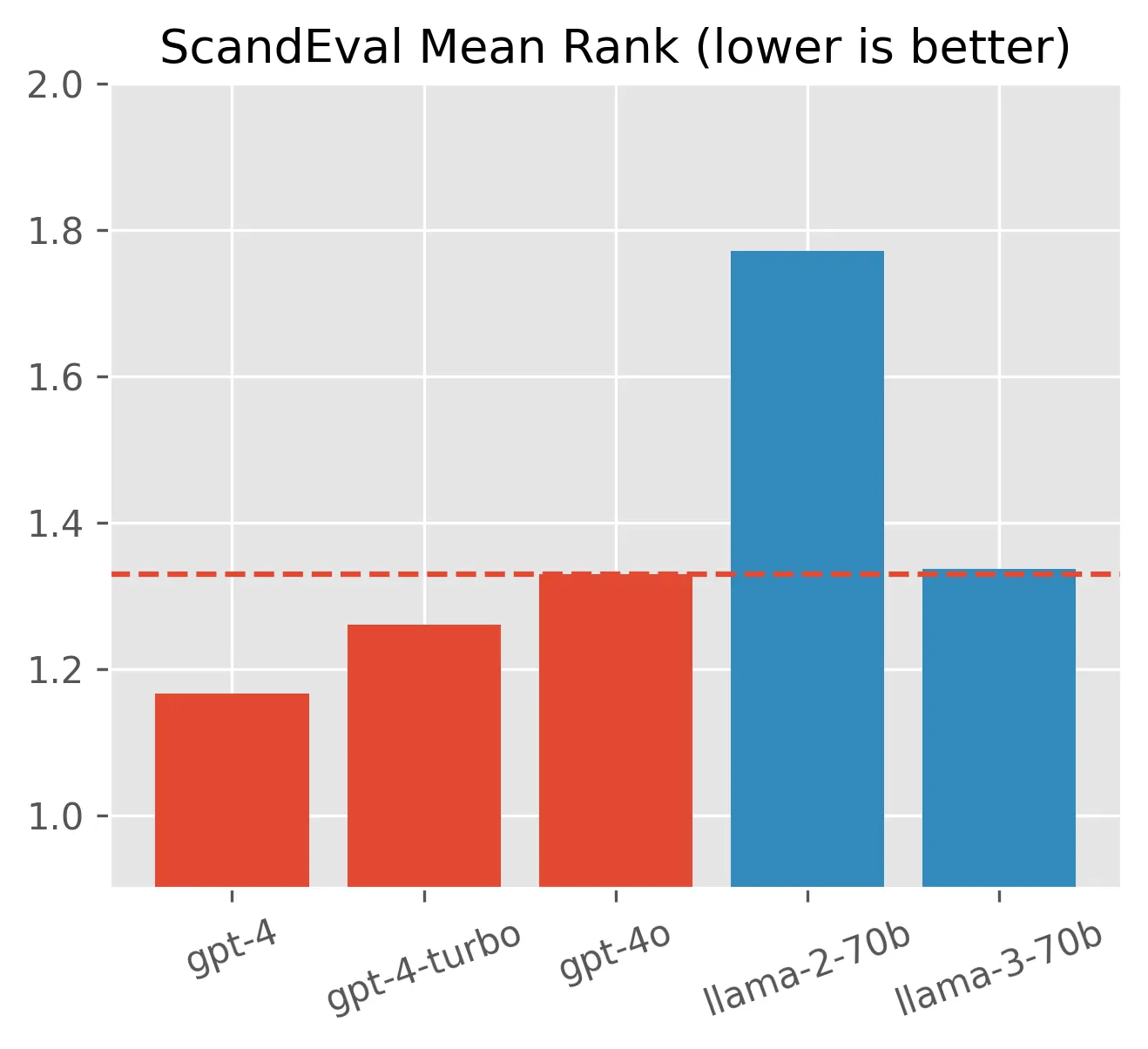
In any case, it does seem like OpenAI is working hard on cutting down costs, which unfortunately results in worse models for us all. It even seems like open models have caught up - here is a plot of the average ScandEval ran for the languages considered in this blog post (English, German, Dutch, Danish, Swedish and Norwegian):
This work is part of the EU Horizon project TrustLLM.



