Scales 101 - Part IV
Leaving a Gap
Posted on October 27, 2017
So far we’ve characterised the scaled pointclasses among the projective hierarchy as well as establishing Steel’s result that $\Sigma_1^{J_\alpha(\mathbb R)}$ is scaled for all $\alpha>0$ such that $\text{Det}(J_\alpha(\mathbb R)$. We now move on to boldface territory, finishing off this series on scales.
This post is part of a series on scales:
- Scales 101 - Part I: What & Why?
- Scales 101 - Part II: Where & How?
- Scales 101 - Part III: Moving to L®
- Scales 101 - Part IV: Leaving a Gap
We’re going to need the notion of a gap, where we say that an interval $[\alpha,\beta]$ is a gap if $J_\alpha(\mathbb R)\prec_1^{\mathbb R} J_\beta(\mathbb R)$ and this stops being the case when we extend the interval. Here $\prec_1^{\mathbb R}$ means that the left-hand side is a $\Sigma_1$-elementary substructure with parameters allowed from $\mathbb R\cup\{V_{\omega+1}\}$. This is also sometimes called a $\Sigma_1$-gap, but since we’re not going to need the $\Sigma_n$-gaps for anything we stick to the ‘gap’ terminology.
For convenience we also say that $[(\bf\delta^2_1)^{L(\mathbb R)},\Theta^{L(\mathbb R)}]$ is a gap, where we note that $(\bf\delta^2_1)^{L(\mathbb R)}$ is least such that $J_{(\bf\delta^2_1)^{L(\mathbb R)}}(\mathbb R)\prec_1^{\mathbb R} L(\mathbb R)$. Our first lemma states that gaps can be used to characterise ordinals.
Lemma. The gaps partition the ordinals below $\Theta^{L(\mathbb R)}$.
Proof. Let $\gamma<\Theta^{L(\mathbb R)}$ and let $\alpha\leq\gamma$ be least such that $J_\alpha(\mathbb R)\prec_1^{\mathbb R}J_\gamma(\mathbb R)$ and $\beta\geq\alpha$ the supremum of all $\delta<\Theta^{L(\mathbb R)}$ such that $J_\gamma(\mathbb R)\prec_1^{\mathbb R}J_\delta(\mathbb R)$. Then $[\alpha,\beta]$ is clearly a gap with $\gamma\in[\alpha,\beta]$.
Now say that two gaps $[\alpha,\beta]$ and $[\alpha’,\beta’]$ overlapped at some $\gamma$. This means that $J_\alpha(\mathbb R)\prec_1^{\mathbb R}J_\gamma(\mathbb R)$ and $J_\gamma(\mathbb R)\prec_1^{\mathbb R}J_{\beta’}(\mathbb R)$ but $J_\alpha(\mathbb R)\not\prec_1^{\mathbb R}J_{\beta’}(\mathbb R)$. But this is impossible as we’re requiring that all parameters lie in $\mathbb R\cup\{V_{\omega+1}\}$. QED
We can thus split an arbitrary $\alpha<\Theta^{L(\mathbb R)}$ into three cases:
- $\alpha$ begins a gap;
- $\alpha$ ends a gap;
- $\alpha$ lies properly within a gap.
When it comes to finding scaled pointclasses, the following result shows that we can disregard the third possibility.
Theorem (Martin). Let $[\alpha,\beta]$ be a gap and assume $\text{Det}(J_{\alpha+1}(\mathbb R))$. Then there’s a $\Pi_1^{J_\alpha(\mathbb R)}$ subset of $\mathbb R\times\mathbb R$ with no $\bf\Sigma_1^{J_\beta(\mathbb R)}$ uniformisation. In particular, if $\gamma\in(\alpha,\beta)$ and $\text{Det}(J_\gamma(\mathbb R))$ then none of the classes $\bf\Sigma_n^{J_\gamma(\mathbb R)}$ or $\bf\Pi_1^{J_\gamma(\mathbb R)}$ are scaled, for any $n<\omega$.
We thus only have to analyse case 1 and 2. Let’s start off with the first case where $\alpha$ begins a gap. Again we may assume $\alpha>0$, since we already covered the $\alpha=0$ case. The case where $n=1$ turns out to just be a corollary of the lightface result that we covered last time.
Corollary. If $\alpha>0$ begins a gap and $\text{Det}(J_\alpha(\mathbb R))$ holds then $\bf\Sigma_1^{J_\alpha(\mathbb R)}$ has the scale property.
Proof. Note that since $\alpha$ begins a gap there’s a partial $\bf\Sigma_1^{J_\alpha(\mathbb R)}$ surjection $\mathbb R\to J_\alpha(\mathbb R)$. Indeed, by forming the hull $H:=\text{cHull}1^{J\alpha(\mathbb R)}(\mathbb R\cup\{V_{\omega+1}\})$ we see that $H=J_\alpha(\mathbb R)$ by condensation and minimality, as $\alpha$ begins a gap, so the associated $\bf\Sigma_1^{J_\alpha(\mathbb R)}$ Skolem function is then as desired. Steel’s lightface result then gives the desired scale. QED
When we move to $n>1$ then the existence of scales turn out to depend on the admissibility of $\alpha$, where we say that $\alpha$ is admissible if $J_\alpha(\mathbb R)\models\textsf{KP}$, or equivalently that there’s no $\Sigma_1^{J_\alpha(\mathbb R)}$ cofinal map $\gamma\to\omega\alpha$ for some $\gamma<\omega\alpha$. Technically speaking the terminology admissible is reserved for the $L$-hierarchy, so we could’ve called it something like $\mathbb R$-admissible – but as we won’t need to consider the $L$-variants of admissibility, there won’t be any confusion. Now, the key lemma is the following.
Lemma. Assume that $\alpha$ begins a gap and is inadmissible (not admissible). Then for all $n\geq 1$,
$$ \bf\Sigma_{n+1}^{J_\alpha(\mathbb R)}=\exists^{\mathbb R}\bf\Pi_n^{J_\alpha(\mathbb R)}\text{ and }\bf\Pi_{n+1}^{J_\alpha(\mathbb R)}=\forall^{\mathbb R}\bf\Sigma_n^{J_\alpha(\mathbb R)}. $$
I won’t give the proof here (a full proof can be found in my note), but the idea is that the conjunction of $\alpha$ beginning a gap and being inadmissible implies that we get a cofinal map $\mathbb R\to\omega\alpha$. The above two results then give us that $\bf\Sigma_{2n+1}^{J_\alpha(\mathbb R)}$ and $\bf\Pi_{2n+2}^{J_\alpha(\mathbb R)}$ have the scale property, whenever $\alpha>0$ begins a gap, is inadmissible, $\text{Det}(J_{\alpha+1}(\mathbb R))$ holds and $n<\omega$. To see that inadmissibility is necessary, Martin comes to the rescue again.
Theorem (Martin). Assume $\alpha$ begins a gap, is admissible and $\text{Det}(J_{\alpha+1}(\mathbb R))$ holds. Then there’s a $\Pi_1^{J_\alpha(\mathbb R)}$ subset of $\mathbb R\times\mathbb R$ with no uniformisation in $J_{\alpha+1}(\mathbb R)$. In particular, none of the classes $\bf\Sigma_n^{J_\alpha(\mathbb R)}$ or $\bf\Pi_n^{J_\alpha(\mathbb R)}$ are scaled for $n>1$.
This finishes the case where $\alpha$ begins a gap. We’ll need a definition for the gap endings. We say that a gap $[\alpha,\beta]$ is strong if for every $b\in J_\beta(\mathbb R)$ there’s a $\gamma<\beta$ and an $a\in J_\gamma(\mathbb R)$ such that for every $\varphi(v)\in\Sigma_1\cup\Pi_1$ it holds that
$$ J_\gamma(\mathbb R)\models\varphi[a]\text{ iff }J_\beta(\mathbb R)\models\varphi[b]. $$
It turns out that for us to have any chance of finding scales at the end of gaps, we have to require our gaps to be weak. Martin returns with a counterexample.
Theorem (Martin). Let $[\alpha,\beta]$ be a strong gap and assume $\text{Det}(J_{\alpha+1}(\mathbb R))$. Then there’s a $\Pi_1^{J_\alpha(\mathbb R)}$ relation which has no uniformisation in $J_{\beta+1}(\mathbb R)$. In particular, none of the classes $\bf\Sigma_n^{J_\beta(\mathbb R)}$ or $\bf\Pi_n^{J_\beta(\mathbb R)}$ are scaled for $n<\omega$.
So we can focus solely on weak gaps then. Furthermore, if $\rho_k(J_\beta(\mathbb R))\neq\mathbb R$ (i.e. we’re not projecting to 0) for every $k\leq n$ then we don’t get any new subsets of reals of interest, meaning that
$$ \bf\Sigma_n^{J_\beta(\mathbb R)}=\bf\Sigma_n^{J_\alpha(\mathbb R)}\text{ and } \bf\Pi_n^{J_\beta(\mathbb R)}=\bf\Pi_n^{J_\alpha(\mathbb R)}, $$
just reducing it to the begins-a-gap case. Taking this into account, we do have the following theorem, whose proof is a technical tour de force based on the same ideas as the lightface proof that I’ve written up here.
Theorem (Steel). Let $[\alpha,\beta]$ be a weak gap and assume $\text{Det}(J_{\alpha+1}(\mathbb R))$. If $n<\omega$ is least such that $\rho_n(J_\beta(\mathbb R))=\mathbb R$ then
$$ \bf\Sigma_{n+2k}^{J_\beta(\mathbb R)}\text{ and }\bf\Pi_{n+2k+1}^{J_\beta(\mathbb R)} $$
are scaled, for every $k<\omega$.
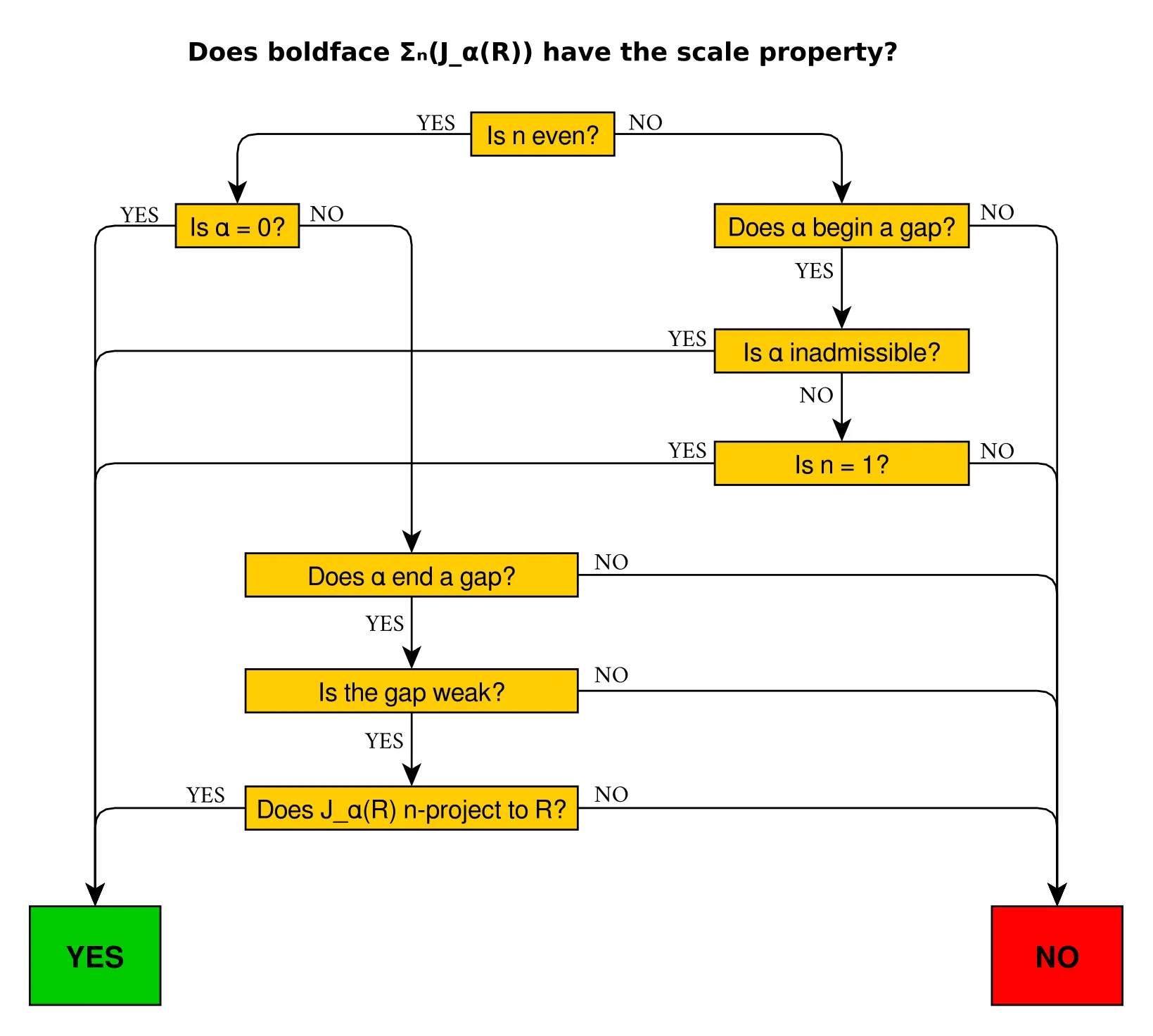
Aaaand that finishes the complete characterisation, which is used to organise the cases in the core model induction. So if you’re ever wondering if $\bf\Sigma_n^{J_\alpha(\mathbb R)}$ is scaled, we can now use the following handy flowchart (pdf available here):